Superskalárna architektúra CPU: definícia a princíp fungovania
Objavte, ako superskalárna architektúra CPU zvyšuje výkon paralelným vykonávaním inštrukcií, princípy dispečingu, funkčné jednotky a optimalizácie.
Superskalárny dizajn CPU umožňuje formu paralelného výpočtu nazývaného paralelizmus na úrovni inštrukcií. Cieľom je, aby jadro vykonalo viac inštrukcií za rovnakú taktovaciu frekvenciu — teda zvýšiť celkový výkon bez nutnosti zvyšovať takt. To sa dosahuje spúšťaním viacerých inštrukcií súčasne (tzv. dispečing inštrukcií) na duplicitných funkčných jednotkách v jadre.
Každá funkčná jednotka predstavuje konkrétny vykonávací prostriedok v CPU, napríklad aritmeticko-logická jednotka (ALU), jednotka s pohyblivou rádovou čiarkou (FPU), bitový posunovač alebo násobička. Keď sú k dispozícii viaceré takéhoto jednotky, procesor môže súčasne vykonávať nezávislé inštrukcie.
Väčšina superskalárnych procesorov je tiež pipelínová, hoci teoreticky je možné mať nepipelínový superskalárny procesor alebo pipelínový nesuperskalárny procesor. Pipelínovanie rozdeľuje vykonanie inštrukcie na viacero fáz (napr. fetch, decode, execute, memory, writeback), čo zvyšuje hustotu spracovania inštrukcií v čase.
Galéria obrázkov
2 Obrázky
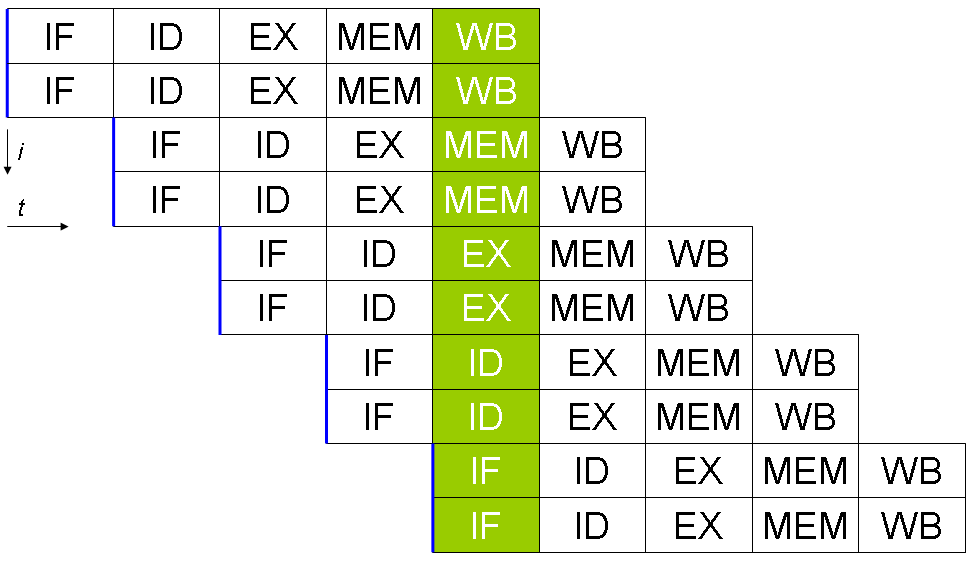
Aby superskalárna technika fungovala
Superskalárnu techniku umožňuje kombinácia viacerých hardvérových funkcií jadra CPU:
- Pokyny pochádzajú z usporiadaného zoznamu pokynov a sú načítavané vo vstupe do jadra.
- Hardvér procesora dokáže zistiť, ktoré inštrukcie majú aké dátové závislosti (adresné, dátové alebo kontrolné závislosti) a ktoré sú nezávislé a teda spustiteľné paralelne.
- Procesor dokáže čítať a dekódovať viac inštrukcií za jeden hodinový cyklus — rozlišujeme šírku vydávania (issue width) a počet naraz spracovávaných inštrukcií.
Superskalárnosť vs. skalárne a vektorové procesory
Každá inštrukcia vykonaná skalárnym procesorom spracúva jednu alebo pár dátových položiek naraz, zatiaľ čo vektorový (SIMD) procesor spracúva jednu inštrukciu nad množinou dátových prvkov. Superskalárny procesor kombinuje tieto prístupy:
- Každá inštrukcia spracúva jednu dátovú položku (skalárny model).
- Vnútri jedného jadra sú však viaceré duplicitné funkčné jednotky, takže viac inštrukcií — každá nad svojou dátovou položkou — môžu byť spracované súčasne.
Funkcie dispečera a mechanizmy pre zvýšenie paralelizmu
V superskalárnom procesore dispečer inštrukcií (instruction dispatcher) číta inštrukcie z pamäte, určuje ich závislosti a rozhoduje, ktoré inštrukcie možno spustiť paralelne. Kľúčové mechanizmy, ktoré zvyšujú efektivitu dispečingu, zahŕňajú:
- Statické a dynamické plánovanie (static vs. dynamic scheduling) — pri dynamickom plánovaní sa rozhoduje počas behu programu, čo zvyšuje adaptabilitu k reálnemu toku inštrukcií.
- Out-of-order execution (vykonávanie mimo poradia) — inštrukcie sa môžu vykonávať, ak sú pripravené, aj keď sú pôvodne za inými inštrukciami v poradí programu.
- Register renaming — odstraňuje falošné závislosti spôsobené zdieľaním registrov (WAW a WAR), čím zvyšuje možnosť paralelizmu.
- Rezervačné stanice a Tomasulov algoritmus — umožňujú dynamickú distribúciu inštrukcií do funkčných jednotiek a riešia závislosti za behu.
- Reorder buffer — zabezpečuje, že výsledky sa zapíšu do architektonických registrov v správnom poradí (preserving precise exceptions).
- Predikcia skokov (branch prediction) a spekulatívne vykonávanie — znižujú prestoje spôsobené vetvením programu.
Obmedzenia a problémy
Superskalárna architektúra prináša vyšší výkon, ale narazí na niekoľko limitácií:
- Dátové závislosti (RAW, WAR, WAW) môžu zabrániť súbežnému vykonávaniu inštrukcií.
- Strukturálne konflikty — používanie tej istej funkčnej jednotky dvoma inštrukciami súčasne.
- Kontrolné závislosti spôsobené vetvením programu — zlé predikcie skokov vedú k vyprázdneniu pipeline a stratám cyklov.
- Obmedzenia pamäte — dlhé latencie prístupu do pamäte a cache misses môžu výrazne znížiť efektívnu vyťaženosť funkčných jednotiek.
- Komplexnosť návrhu — širší dispečing, renaming a ROB zvyšujú zložitosť, spotrebu energie a plochu čipu.
Metriky výkonu a praktické ukazovatele
Dôležité ukazovatele pre superskalárne CPU sú:
- IPC (instructions per cycle) — priemerný počet vykonaných inštrukcií za jeden takt. Ideálny IPC sa rovná issue width (maximálny počet inštrukcií, ktoré možno vydať za cyklus), ale reálne býva nižší kvôli závislostiam a iným obmedzeniam.
- Issue width — napr. dvojsmerný, štvorprúdový (4-way) atď.; udáva, koľko inštrukcií môže dispečer teoreticky poslať do funkčných jednotiek v jednom cykle.
- Faktická vyťaženosť funkčných jednotiek — percento času, keď sú jednotky v činnosti.
Typy superskalárnych dizajnov a porovnanie
Existujú rôzne prístupy k architektúre:
- V porovnaní s VLIW (Very Long Instruction Word) — VLIW presúva väčšinu plánovania paralelizmu na kompilátor, zatiaľ čo superskalárny dizajn robí dynamické plánovanie v hardvéri.
- Superskalárne jednotky môžu byť kombinované so SIMD jednotkami (napríklad vektorové rozšírenia), čím sa dosahuje paralelizmus na dvoch úrovniach súčasne.
Vývoj a súčasné použitie
V praxi sú moderné univerzálne procesory (x86, ARM a pod.) prevažne superskalárne a pipelínové. Typický superskalárny procesor môže obsahovať niekoľko ALU, FPU a ďalších špecializovaných jednotiek; napríklad konfigurácie s 2–4 ALU a 1–2 FPU boli bežné. Pokročilé návrhy môžu mať aj viacnásobné SIMD jednotky či špecializované jednotky pre kryptografiu alebo vektorové operácie.
Návrh superskalárneho procesora sa zameriava na zlepšenie presnosti dispečingu inštrukcií a na udržanie čo najvyššieho počtu aktívnych funkčných jednotiek. Ak dispečer nedokáže udržať jednotky obsadené (napr. kvôli častým závislostiam alebo cache missom), výsledný výkon bude pod maximálnou možnou hranicou.
Pre praktické prípady optimalizácie softvéru a kompilátorov je dôležité písať a generovať kód, ktorý minimalizuje závislosti, zlepšuje lokalitu pamäte a využíva dostupné paralelné prostriedky procesora — tým sa dosiahne vyššie reálne IPC a lepšie využitie superskalárnej architektúry.


Obmedzenia
Zlepšenie výkonu pri návrhu superskalárnych procesorov je obmedzené dvoma vecami:
- Úroveň zabudovaného paralelizmu v zozname inštrukcií
- Zložitosť a časové náklady na dispečing a kontrolu závislosti údajov.
Aj za predpokladu nekonečne rýchlej kontroly závislostí v bežnom superskalárnom procesore, ak má samotný zoznam inštrukcií veľa závislostí, tiež by to obmedzilo možné zlepšenie výkonu, takže množstvo zabudovaného paralelizmu v kóde je ďalším obmedzením.
Bez ohľadu na to, aká je rýchlosť dispečera, existuje praktický limit, koľko inštrukcií možno súčasne odoslať. Hardvérový pokrok síce umožní viac funkčných jednotiek (napr. ALU) na jedno jadro CPU, ale problém kontroly závislostí inštrukcií narastá do takej miery, že dosiahnuteľný limit superskalárneho dispečingu je o niečo menší. -- Pravdepodobne rádovo päť až šesť súčasne odosielaných inštrukcií.
Alternatívy
- Simultánny multithreading: často označovaný skratkou SMT je technika na zvýšenie celkovej rýchlosti superskalárnych procesorov. SMT umožňuje vykonávať viacero nezávislých vlákien, aby sa lepšie využili zdroje dostupné v modernom superskalárnom procesore.
- Viacjadrové procesory: superskalárne procesory sa od viacjadrových procesorov líšia tým, že viaceré redundantné funkčné jednotky nie sú celé procesory. Jeden superskalárny procesor sa skladá z pokročilých funkčných jednotiek, ako sú ALU, celočíselná násobička, celočíselný posunovač, jednotka s pohyblivou rádovou čiarkou (FPU) atď. Môže existovať viacero verzií každej funkčnej jednotky, aby bolo možné vykonávať mnoho inštrukcií paralelne. Tým sa líši od viacjadrových procesorov, ktoré súbežne spracúvajú inštrukcie z viacerých vlákien, jedno vlákno na jadro.
- Pipelined procesory: Superskalárne procesory sa tiež líšia od pipelined procesorov, kde môže byť viacero inštrukcií súčasne v rôznych fázach vykonávania.
Rôzne alternatívne techniky sa navzájom nevylučujú - možno ich kombinovať (a často sa aj kombinujú) v jednom procesore, takže je možné navrhnúť viacjadrový procesor, v ktorom je každé jadro nezávislým procesorom s viacerými paralelnými superskalárnymi pipelines. Niektoré viacjadrové procesory obsahujú aj vektorové funkcie.
Súvisiace stránky
- Paralelné výpočty
- Paralelizmus na úrovni inštrukcií
- Simultánne viacvláknové spracovanie (SMT)
- Viacjadrové procesory
Otázky a odpovede
Otázka: Čo je to superskalárna technológia?
Odpoveď: Superskalárna technológia je forma základných paralelných výpočtov, ktorá umožňuje spracovať viac ako jednu inštrukciu v každom hodinovom cykle pomocou viacerých vykonávacích jednotiek súčasne.
Otázka: Ako funguje superskalárna technológia?
Odpoveď: Superskalárna technológia zahŕňa inštrukcie prichádzajúce do procesora v poradí, hľadanie dátových závislostí počas behu a načítanie viac ako jednej inštrukcie v každom takte.
Otázka: Aký je rozdiel medzi skalárnymi a vektorovými procesormi?
Odpoveď: V skalárnom procesore inštrukcie zvyčajne pracujú s jednou alebo dvoma dátovými položkami naraz, zatiaľ čo vo vektorovom procesore inštrukcie zvyčajne pracujú s mnohými dátovými položkami naraz. Superskalárny procesor je kombináciou oboch, pretože každá inštrukcia spracúva jednu dátovú položku, ale viac ako jedna inštrukcia beží naraz, takže procesor spracúva mnoho dátových položiek naraz.
Otázka: Akú úlohu zohráva presný dispečer inštrukcií v superskalárnom procesore?
Odpoveď: Presný dispečer inštrukcií je pre superskalárny procesor veľmi dôležitý, pretože zabezpečuje, aby boli vykonávacie jednotky vždy obsadené prácou, ktorá bude pravdepodobne potrebná. Ak dispečer inštrukcií nie je presný, potom sa môže stať, že časť práce bude musieť byť zahodená, čo by spôsobilo, že procesor nebude rýchlejší ako škálovací procesor.
Otázka: V ktorom roku sa všetky bežné procesory stali superskalárnymi?
Odpoveď: Všetky bežné procesory sa stali superskalárnymi v roku 2008.
Otázka: Koľko ALU, FPU a SIMD jednotiek môže byť na normálnom CPU?
Odpoveď: V bežnom CPU môžu byť až 4 ALU, 2 FPU a 2 jednotky SIMD.
Súvisiace články
Autor
AlegsaOnline.com Superskalárna architektúra CPU: definícia a princíp fungovania Leandro Alegsa
URL: https://sk.alegsaonline.com/art/95080