Lineárna regresia: definícia, princípy a praktické použitie
Lineárna regresia: jasná definícia, princípy a praktické použitie v predikcii, analýze vzťahov a optimalizácii modelov — praktický návod pre začiatočníkov aj profesionálov.
Lineárna regresia je štatistická metóda na modelovanie a kvantifikáciu vzťahu medzi závislou premennou a jednou alebo viacerými vysvetľujúcimi premennými pomocou priamej funkcie (priamky alebo hyperroviny). Je to špeciálny prípad regresnej analýzy, pri ktorom je model lineárny voči neznámym parametrom.
Historicky lineárna regresia patrí medzi prvé typy regresnej analýzy, ktoré sa dôsledne skúmali, pretože modely, ktoré sú lineárne voči svojim parametrom, sa ľahšie fitujú a analyzujú. Taktiež sa ľahšie odhadujú a interpretuú ich štatistické vlastnosti (variancie odhadov, konštrukcia intervalov spoľahlivosti a testovanie hypotéz).
Galéria obrázkov
1 Obrázok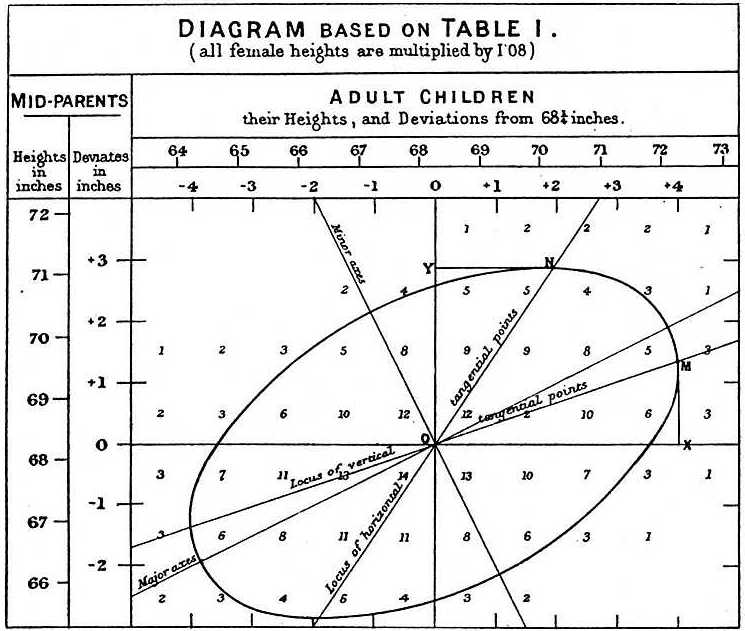
Základná formulácia
Pre jednoduchú lineárnu regresiu s jednou vysvetľujúcou premennou platí matematické zobrazenie
y = β0 + β1 x + ε,
kde y je závislá premenná, x vysvetľujúca premenná, β0 a β1 sú parametre (intercept a sklon) a ε je náhodná chyba (reziduum).
Pre viacnásobnú lineárnu regresiu so p premennými je model
y = β0 + β1 x1 + ... + βp xp + ε.
V maticovej notácii sa model zapisuje ako y = Xβ + ε a najbežnejší odhad parametrov pomocou metódy najmenších štvorcov (OLS) dáva uzávierkový vzorec β̂ = (X'X)^{-1} X'y, pokiaľ matica X'X je neinvertovateľná.
Metódy odhadovania a kritériá prispôsobenia
Najčastejšie sa odhady parametrov získavajú minimalizáciou súčtu štvorcov rezíduí — metóda najmenších štvorcov. Cieľom je, aby zvislá vzdialenosť medzi priamkou a dátovými bodmi bola čo najmenšia. Existujú však aj alternatívne prístupy:
- Minimalizácia súčtu absolútnych odchýlok (least absolute deviations) — robusnejšia voči odľahlým hodnotám.
- Minimalizácia nejakej inej normy alebo využitie robustných odhadov rezíduí.
- Penalizované metódy, ktoré pridávajú regulačný člen do stratovej funkcie, napr. hrebeňová (ridge) a LASSO regresia — užitočné pri veľkom počte premenných alebo kolinearite.
Je dôležité rozlíšiť „lineárny model“ (lineárny voči parametrom) od „metódy najmenších štvorcov“ — tie spolu často idú ruka v ruke, ale nie sú synonymá. Metóda najmenších štvorcov sa dá použiť aj pre niektoré nelineárne modely.
Interpretácia parametrov a predikcia
Koeficient βj v lineárnom modeli pri ostatných premenných fixných interpretuje priemernú zmenu závislej premennej y pri jednotkovej zmene premenné Xj. Intercept β0 je očakávaná hodnota y, keď sú všetky Xj nulové (ak má tento význam v danej aplikácii).
Po odhade modelu môžeme pre novú hodnotu vstupných premenných X* získať predikciu ŷ = X* β̂. Pri predikcii rozlišujeme interval spoľahlivosti pre stredný očakávaný výsledok (confidence interval) a širší prediktívny interval pre jednotlivé nové pozorovania, ktorý zahrňuje variabilitu rezíduí.
Predpoklady modelu a diagnostika
Pre klasickú inferenciu (t-testy, F-test, intervaly spoľahlivosti) sa zvyčajne predpokladá:
- lineárny vzťah medzi vysvetľujúcimi premennými a očakávaním y,
- exogenita (nezávislosť chýb od vysvetľujúcich premenných),
- homoskedasticita — konštantná disperzia rezíduí,
- nezávislosť rezíduí (žiadna autokorelácia),
- pri inferencii často predpoklad normálneho rozdelenia chýb.
Bežné diagnostické nástroje zahŕňajú grafy rezíduí (rezíduá vs predikované hodnoty), testy heteroskedasticity (napr. Breusch–Pagan), testy autokorelácie (Durbin–Watson), hodnotenie multikolinearity pomocou VIF (variance inflation factor), analýzu vplyvných bodov cez Cookovu vzdialenosť a leverage hodnoty. Ak sú predpoklady porušené, používajú sa robustné štandardné chyby, transformácie premenných, vážené najmenšie štvorce alebo iné modely.
Rozšírenia a regulárne metódy
Pri veľkom počte vysvetľujúcich premenných alebo pri kolinearite sa používajú penalizačné metódy:
- Ridge (hrebeňová) regresia — pridá L2 penalizáciu na veľkosť koeficientov, znižuje varianciu odhadov.
- LASSO — pridá L1 penalizáciu, vedie k riedkym riešeniam a funguje ako nástroj na výber premenných.
- Elastic Net — kombinuje L1 a L2 penalizáciu.
Ďalšie rozšírenia: regresia s interakčnými členmi, polynomiálna regresia (pre zakrivené vzťahy), logistická regresia pre binárne závislé premenné (nie je lineárna v y, ale lineárna v logit-transformácii) a generalizované lineárne modely (GLM).
Praktické použitie
Lineárna regresia sa používa v mnohých oblastiach — ekonómia (odhad elasticity, analýza cien), medicína a epidemiológia (vplyv rizikových faktorov), sociálne vedy (vplyv vzdelania na príjem), inžinierstvo (kalibrácie, modelovanie vzťahov), strojové učenie (základné regresné modely, baseline). Typické úlohy sú:
- vytvorenie predikčného modelu pre prognózu a odhad budúcich hodnôt,
- kvantifikácia sily vzťahu medzi y a jednotlivými Xj, testovanie hypotéz o významnosti premenných,
- výber relevantných premenných a odhaľovanie redundantných informácií medzi vysvetľujúcimi premennými.
Najlepšie postupy
- Pred modelovaním skontrolujte dáta (chýbajúce hodnoty, extrémy), vykonajte exploratívnu analýzu.
- Zvážte transformácie (log, škvorcová korekcia) alebo pridanie interakčných členov ak vzťah nie je striktne lineárny.
- Pri viacnásobnej regresii sledujte multikolinearitu a použite regulačné metódy alebo selekciu premenných podľa potreby.
- Vyhodnocujte model nielen podľa R², ale aj pomocou upraveného R², AIC/BIC, a pomocou validačných techník (k‑fold cross‑validation) pri predikčných úlohách.
- Vždy rozlišujte medzi koreláciou a kauzalitou; lineárny model ukáže asociácie, nie nevyhnutne kauzálne vzťahy, pokiaľ študijný dizajn neumožňuje kauzálne závery.
Lineárna regresia je jednoduchý, ale veľmi silný nástroj — poskytuje rýchly a interpretabile výsledok, ktorý slúži ako dobrý východiskový bod pre zložitejšie modelovanie. Pri správnom overení predpokladov a úprave modelu podľa dát dokáže byť spoľahlivým nástrojom pre analýzu a predikciu.

Použitie
Ekonomika
Lineárna regresia je hlavným analytickým nástrojom v ekonómii. Používa sa napríklad na odhad výdavkov na spotrebu, výdavkov na fixné investície, investícií do zásob, nákupov vývozu krajiny, výdavkov na dovoz, dopytu po držbe likvidných aktív, dopytu po práci a ponuky práce.
Otázky a odpovede
Otázka: Čo je to lineárna regresia?
Odpoveď: Lineárna regresia je spôsob, ako sa pomocou matematiky pozrieť na to, ako sa niečo zmení, keď sa zmenia iné veci. Používa závislú premennú a jednu alebo viac vysvetľujúcich premenných na vytvorenie priamky, známej ako "regresná priamka".
Otázka: Aké sú výhody lineárnej regresie?
Odpoveď: Modely, ktoré lineárne závisia od svojich neznámych parametrov, sa ľahšie prispôsobujú ako modely, ktoré sú nelineárne závislé od svojich parametrov. Okrem toho sa ľahšie určujú štatistické vlastnosti výsledných odhadov.
Otázka: Aké sú niektoré praktické spôsoby použitia lineárnej regresie?
Odpoveď: Lineárnu regresiu možno použiť na fitovanie predikčného modelu na pozorované hodnoty (údaje) s cieľom urobiť predpovede, prognózy alebo redukcie. Môže sa použiť aj na kvantifikáciu sily vzťahov medzi premennými a identifikáciu podmnožín údajov, ktoré obsahujú nadbytočné informácie o inej premennej.
Otázka: Ako sa lineárne regresné modely snažia minimalizovať chyby?
Odpoveď: Lineárne regresné modely sa snažia, aby vertikálna vzdialenosť medzi priamkou a dátovými bodmi (rezíduá) bola čo najmenšia. To sa dosahuje minimalizáciou buď súčtu štvorcov rezíduí (najmenšie štvorce), nedostatočnej zhody v nejakej inej norme (najmenšie absolútne odchýlky), alebo minimalizáciou penalizovanej verzie stratovej funkcie najmenších štvorcov (hrebeňová regresia).
Otázka: Je možné, aby lineárne regresné modely neboli založené na najmenších štvorcoch?
Odpoveď: Áno, je možné, aby lineárne regresné modely neboli založené na najmenších štvorcoch, ale aby namiesto toho používali metódy, ako je minimalizácia nedostatočnej zhody v nejakej inej norme (najmenšie absolútne odchýlky) alebo minimalizácia penalizovanej verzie stratovej funkcie najmenších štvorcov (ridge regresia).
Otázka: Sú "lineárny model" a "najmenšie štvorce" synonymá?
Odpoveď: Nie, nie sú to synonymá. Hoci sú úzko prepojené, "lineárny model" sa vzťahuje konkrétne na použitie priamky, zatiaľ čo "najmenšie štvorce" sa vzťahujú konkrétne na snahu minimalizovať chyby tým, že sa zabezpečí minimálna vertikálna vzdialenosť medzi priamkou a dátovými bodmi.
Súvisiace články
Autor
AlegsaOnline.com Lineárna regresia: definícia, princípy a praktické použitie Leandro Alegsa
URL: https://sk.alegsaonline.com/art/58267