Mikroarchitektúra procesora (CPU): definícia, funkcie a rozdiel od ISA
Mikroarchitektúra CPU: jasná definícia, hlavné funkcie a rozdiel medzi mikroarchitektúrou a ISA — prehľadné vysvetlenie pre študentov, vývojárov a IT nadšencov.
V počítačovej technike mikroarchitektúra (niekedy skrátene – µarch alebo uarch) opisuje konkrétne usporiadanie a zapojenie elektrických obvodov v rámci počítača, centrálnej procesorovej jednotky alebo digitálneho signálového procesora. Mikroarchitektúra popisuje interné jednotky, cesty dát, registre, riadiace logiky a všetky ďalšie hardvérové prvky potrebné na vykonávanie inštrukcií tak, aby bol úplne pochopený a opísateľný spôsob činnosti hardvéru.
Vedci často používajú termín organizácia počítača, zatiaľ čo v priemysle sa bežnejšie hovorí o mikroarchitektúre. Mikroarchitektúra a architektúra inštrukčnej sady (ISA) spolu tvoria oblasť počítačovej architektúry — ISA definuje zmluvu medzi softvérom a hardvérom (čo inštrukcie robia), zatiaľ čo mikroarchitektúra určuje, ako sú tieto inštrukcie fyzicky a logicky realizované.
Galéria obrázkov
1 Obrázok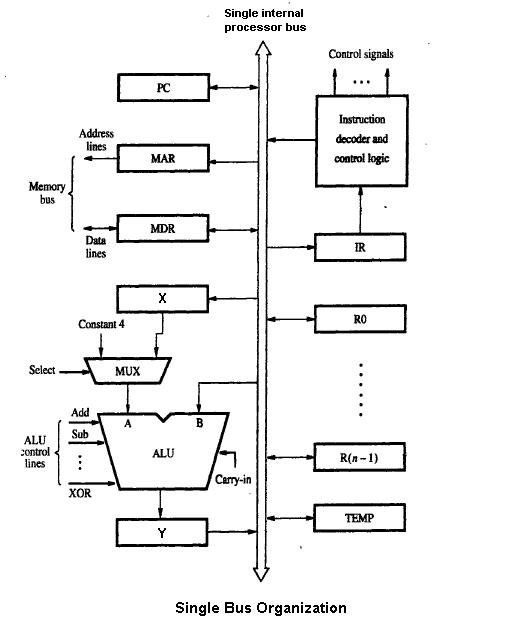
Čo mikroarchitektúra zahŕňa
- Datová cesta (data path): aritmeticko-logická jednotka (ALU), násobiče, jednotky pre plávajúcu desatinnú čiarku a ďalšie výpočtové bloky.
- Registre a registratúra: súbor registrov, špeciálne registre stavu a riadiace registre.
- Riadiaca logika: generovanie signálov, ktoré koordinujú vykonávanie inštrukcií.
- Cache a pamäťová hierarchia: L1/L2/L3 cache, TLB (translation lookaside buffer) a mechanizmy pre konzistenciu pamäte.
- Jednotky pre prístup k pamäti a I/O: arbitrácia, riadenie prenosov a DMA.
- Predikcia vetvenia a jednotky pre paralelizmus: branch predictors, pipeline, superskalárne vydávanie, out-of-order execution a reorder buffer.
- Mikrokód alebo dekompozícia inštrukcií: u niektorých dizajnov (napríklad klasické CISC implementácie) sú zložité inštrukcie rozložené na jednoduchšie mikrooperácie.
Hlavné princípy a techniky
- Pipelining – rozdelenie vykonávania inštrukcie do viacerých etáp (fetch, decode, execute, memory, write-back), čím sa zvyšuje priepustnosť procesora.
- Superskalárnosť – súčasné vydávanie viacerých inštrukcií za cyklus pomocou viacerých výkonných jednotiek.
- Out-of-order execution – vykonávanie inštrukcií v poradí, ktoré maximalizuje využitie jednotiek, pričom výsledky sú zoraďované tak, aby sa zachovala semantika programu.
- Predikcia vetvenia – mechanizmy na predpovedanie výsledku rozvetvení za účelom zníženia strát spôsobených prerušovaním pipeline.
- Spekulatívne vykonávanie – vykonávanie potenciálnych ciest programu pred potvrdením, čo zvyšuje výkon, ale vyžaduje ochranné mechanizmy (napr. po zistení zraniteľností typu Spectre/Meltdown boli zavedené opravy).
Mikroarchitektúra vs. ISA
ISA (architektúra inštrukčnej sady) definuje, aké inštrukcie sú k dispozícii pre programátora, formát inštrukcií, veľkosť registrov, režimy adresovania a pravidlá volaní funkcií. Je to zmluva medzi softvérom (kompilátormi, operačnými systémami) a hardvérom. Mikroarchitektúra potom túto zmluvu implementuje — rôzne mikroarchitektúry môžu realizovať tú istú ISA, pričom sa líšia v rýchlosti, spotrebe energie, ploche čipu a ďalších vlastnostiach.
Príklad: ISA x86 je implementovaná v rôznych mikroarchitektúrach (Intel Skylake, AMD Zen), pričom každá z nich používa odlišné techniky pre pipeline, cache a paralelizmus, aby dosiahla rôzne výkony a energetickú efektívnosť.
Druhy implementácií
- Hardvérová (hardwired) riadiaca logika – rýchle, nízke latencie, často používané v jednoduchších alebo rýchlostne kritických dizajnoch.
- Mikrokód – zložité inštrukcie sú preložené do sekvencií mikroinštrukcií; umožňuje flexibilitu a jednoduchšie zmeny v správaní inštrukcií, ale môže byť pomalší.
- RISC vs. CISC – RISC (napr. ARM, RISC-V) preferuje jednoduché, rýchle inštrukcie, ktoré sa dobre mapujú na pipeline; CISC (napr. tradičné x86) má bohatšiu množinu inštrukcií, často implementovanú cez mikrooperácie.
Dizajnérske kompromisy a obmedzenia
- Výkon vs. spotreba energie – vysoký výkon zvyčajne znamená vyššiu spotrebu a väčšiu tepelnú záťaž; v mobilných zariadeniach je často priorita energetická efektívnosť.
- Komplexnosť vs. spoľahlivosť – zložité mechanizmy (OOO, špeculatívne vykonávanie) zvyšujú riziko chýb a zraniteľností, vyžadujú robustné overovacie a bezpečnostné mechanizmy.
- Veľkosť čipu a cena – viac jednotiek a väčšie cache zvyšujú plochu čipu a náklady na výrobu.
Praktické aspekty a príklady
V praxi sa mikroarchitektúra navrhuje podľa cieľa produktu: serverové procesory kladú dôraz na viacjadrový výkon a vysoko paralelné vykonávanie, mobilné jadra prioritizujú spotrebu energie a tepelnú efektívnosť. Známe mikroarchitektúry zahŕňajú napríklad Intel Skylake, AMD Zen, ARM Cortex‑A línie alebo rôzne implementácie RISC‑V.
Zhrnutie
Mikroarchitektúra je vnútorný dizajn procesora — súbor rozhodnutí o tom, ako bude hardware fyzicky realizovať inštrukcie definované ISA. Rôzne mikroarchitektúry môžu dosahovať odlišné výsledky (výkon, spotrebu, cenu) pri zachovaní rovnakého programového rozhrania. Pochopenie mikroarchitektúry je kľúčové pre návrh efektívnych procesorov, ladenie softvéru a optimalizáciu systémov.
Pôvod termínu
Počítače využívajú mikroprogramovanie riadiacej logiky od 50. rokov 20. storočia. Procesor dekóduje inštrukcie a posiela signály po príslušných cestách pomocou tranzistorových spínačov. Bity vnútri mikroprogramových slov riadili procesor na úrovni elektrických signálov.
Termín: mikroarchitektúra sa používal na označenie jednotiek, ktoré boli riadené mikroprogramovými slovami, na rozdiel od termínu: "architektúra", ktorá bola viditeľná a zdokumentovaná pre programátorov. Zatiaľ čo architektúra musela byť zvyčajne kompatibilná medzi generáciami hardvéru, základná mikroarchitektúra sa dala ľahko zmeniť.
Vzťah k architektúre inštrukčnej sady
Mikroarchitektúra súvisí s architektúrou inštrukčnej sady, ale nie je s ňou totožná. Architektúra inštrukčnej sady je blízka programovému modelu procesora, ako ho vidí programátor jazyka assembler alebo autor kompilátora, ktorý zahŕňa model vykonávania, registre procesora, režimy adresovania pamäte, formáty adries a dát atď. Mikroarchitektúra (alebo organizácia počítača) je hlavne štruktúra nižšej úrovne, a preto spravuje veľké množstvo detailov, ktoré sú skryté v programovacom modeli. Opisuje vnútorné časti procesora a ich vzájomnú spoluprácu s cieľom implementovať architektonickú špecifikáciu.
Mikroarchitektonickými prvkami môžu byť všetky prvky od jednotlivých logických hradiel cez registre, vyhľadávacie tabuľky, multiplexory, čítače atď. až po kompletné ALU, FPU a ešte väčšie prvky. Úroveň elektronických obvodov sa zasa môže rozdeliť na detaily na úrovni tranzistorov, ako napríklad aké základné štruktúry stavania hradiel sa používajú a aké typy logickej implementácie (statická/dynamická, počet fáz atď.) sa volia, okrem samotného použitého logického návrhu ich stavajú.
Niekoľko dôležitých bodov:
- Jediná mikroarchitektúra, najmä ak obsahuje mikrokód, môže byť použitá na implementáciu mnohých rôznych inštrukčných sád prostredníctvom zmeny úložiska riadenia. To však môže byť dosť komplikované, aj keď sa zjednoduší pomocou mikrokódu a/alebo tabuľkových štruktúr v ROM alebo PLA.
- Dva stroje môžu mať rovnakú mikroarchitektúru, a teda aj rovnakú blokovú schému, ale úplne odlišnú hardvérovú implementáciu. To riadi úroveň elektronických obvodov a ešte viac fyzickú úroveň výroby (integrovaných obvodov a/alebo diskrétnych komponentov).
- Stroje s rôznymi mikroarchitektúrami môžu mať rovnakú architektúru inštrukčnej sady, a preto sú oba schopné vykonávať rovnaké programy. Nové mikroarchitektúry a/alebo obvodové riešenia spolu s pokrokom vo výrobe polovodičov umožňujú novším generáciám procesorov dosahovať vyšší výkon.
Zjednodušené popisy
Veľmi zjednodušený opis na vysokej úrovni - bežný v marketingu - môže zobrazovať len pomerne základné charakteristiky, ako je šírka zbernice, spolu s rôznymi typmi vykonávacích jednotiek a inými veľkými systémami, ako je predikcia vetiev a vyrovnávacie pamäte, zobrazené ako jednoduché bloky - možno s niektorými dôležitými atribútmi alebo charakteristikami. Niekedy môžu byť zahrnuté aj niektoré podrobnosti týkajúce sa štruktúry potrubia (ako je načítanie, dekódovanie, priradenie, vykonávanie, spätný zápis).
Aspekty mikroarchitektúry
Potrubná dátová cesta je v súčasnosti najčastejšie používaným návrhom dátovej cesty v mikroarchitektúre. Táto technika sa používa vo väčšine moderných mikroprocesorov, mikrokontrolérov a DSP. Pipelined architektúra umožňuje, aby sa viaceré inštrukcie pri vykonávaní prekrývali, podobne ako montážna linka. Potrubie obsahuje niekoľko rôznych stupňov, ktoré sú v návrhoch mikroarchitektúry zásadné. Niektoré z týchto etáp zahŕňajú načítanie inštrukcií, dekódovanie inštrukcií, vykonávanie a spätný zápis. Niektoré architektúry obsahujú aj ďalšie fázy, napríklad prístup do pamäte. Návrh pipeline je jednou z hlavných úloh mikroarchitektúry.
Vykonávacie jednotky sú tiež nevyhnutné pre mikroarchitektúru. Vykonávacie jednotky zahŕňajú aritmetické logické jednotky (ALU), jednotky s pohyblivou rádovou čiarkou (FPU), jednotky load/store a predikciu vetiev. Tieto jednotky vykonávajú operácie alebo výpočty procesora. Výber počtu vykonávacích jednotiek, ich latencie a priepustnosti sú dôležitými úlohami návrhu mikroarchitektúry. Veľkosť, latencia, priepustnosť a konektivita pamätí v rámci systému sú tiež mikroarchitektonické rozhodnutia.
Rozhodnutia o návrhu na úrovni systému, ako napríklad rozhodnutie, či zahrnúť alebo nezahrnúť periférne zariadenia, napríklad radiče pamäte, možno považovať za súčasť procesu návrhu mikroarchitektúry. To zahŕňa rozhodnutia o úrovni výkonu a pripojiteľnosti týchto periférnych zariadení.
Na rozdiel od architektonického návrhu, kde je hlavným cieľom konkrétna úroveň výkonu, pri návrhu mikroarchitektúry sa venuje väčšia pozornosť iným obmedzeniam. Pozornosť sa musí venovať takým otázkam, ako sú:
- Plocha čipu/náklady.
- Spotreba energie.
- Logická zložitosť.
- Jednoduchosť pripojenia.
- Vyrobiteľnosť.
- Jednoduché ladenie.
- Testovateľnosť.
Koncepcie mikroarchitektúry
Vo všeobecnosti všetky CPU, jednočipové mikroprocesory alebo viacčipové implementácie spúšťajú programy vykonávaním nasledujúcich krokov:
- Prečítajte si inštrukciu a dekódujte ju.
- Nájdite všetky súvisiace údaje, ktoré sú potrebné na spracovanie pokynu.
- Spracujte pokyn.
- Výsledky si zapíšte.
Túto na prvý pohľad jednoduchú sériu krokov komplikuje skutočnosť, že hierarchia pamäte, ktorá zahŕňa vyrovnávaciu pamäť, hlavnú pamäť a nevolatilné úložisko, ako sú pevné disky (kde sa nachádzajú inštrukcie programu a údaje), bola vždy pomalšia ako samotný procesor. Krok (2) často prináša oneskorenie (v terminológii procesora často nazývané "stall"), kým dáta dorazia na počítačovú zbernicu. Veľké množstvo výskumu sa venovalo návrhom, ktoré sa týmto oneskoreniam čo najviac vyhýbajú. V priebehu rokov bolo hlavným cieľom návrhu vykonávať viac inštrukcií paralelne, čím sa zvýšila efektívna rýchlosť vykonávania programu. Tieto snahy zaviedli komplikované logické a obvodové štruktúry. V minulosti sa takéto techniky mohli implementovať len na drahých mainframoch alebo superpočítačoch vzhľadom na množstvo obvodov potrebných pre tieto techniky. S rozvojom výroby polovodičov sa čoraz viac týchto techník dalo implementovať na jednom polovodičovom čipe.
Nasleduje prehľad mikroarchitektonických techník, ktoré sú bežné v moderných procesoroch.
Výber súboru inštrukcií
Výber architektúry inštrukčnej sady, ktorá sa má použiť, výrazne ovplyvňuje zložitosť implementácie vysokovýkonných zariadení. V priebehu rokov sa konštruktéri počítačov snažili čo najviac zjednodušiť inštrukčné sady, aby umožnili implementáciu vyšších výkonov tým, že ušetrili úsilie a čas konštruktérov na funkcie, ktoré zvyšujú výkon, namiesto toho, aby ich premrhali na zložitosť inštrukčnej sady.
Návrh inštrukčnej sady prešiel od typov CISC, RISC, VLIW, EPIC. Medzi architektúry, ktoré sa zaoberajú dátovým paralelizmom, patria SIMD a vektory.
Potrubné spájanie inštrukcií
Jednou z prvých a najúčinnejších techník na zvýšenie výkonu je použitie inštrukčnej pipeline. Pri prvých návrhoch procesorov sa všetky vyššie uvedené kroky vykonávali na jednej inštrukcii pred prechodom na ďalšiu. Veľká časť obvodov procesora zostávala v každom kroku nečinná; napríklad obvody dekódovania inštrukcií by boli počas vykonávania nečinné atď.
Potrubia zvyšujú výkon tým, že umožňujú, aby procesorom prechádzalo viacero inštrukcií súčasne. V tom istom základnom príklade by procesor začal dekódovať (krok 1) novú inštrukciu, zatiaľ čo posledná by čakala na výsledky. To by umožnilo "rozbehnúť" až štyri inštrukcie naraz, vďaka čomu by procesor vyzeral štyrikrát rýchlejšie. Hoci dokončenie každej jednej inštrukcie trvá rovnako dlho (stále sú to štyri kroky), procesor ako celok "odstupuje" inštrukcie oveľa rýchlejšie a môže bežať na oveľa vyššej taktovacej frekvencii.
Cache
Zlepšenia vo výrobe čipov umožnili umiestniť na jeden čip viac obvodov a konštruktéri začali hľadať spôsoby, ako ich využiť. Jedným z najbežnejších spôsobov bolo pridávanie stále väčšieho množstva vyrovnávacej pamäte na čip. Cache je veľmi rýchla pamäť, pamäť, ku ktorej sa dá pristupovať za niekoľko cyklov v porovnaní s tým, čo je potrebné na komunikáciu s hlavnou pamäťou. Procesor obsahuje radič vyrovnávacej pamäte, ktorý automatizuje čítanie a zápis z vyrovnávacej pamäte, ak sa údaje už nachádzajú vo vyrovnávacej pamäti, jednoducho sa "objavia", zatiaľ čo ak nie, procesor sa "zastaví", kým ich radič vyrovnávacej pamäte načíta.
Konštrukcie RISC začali pridávať vyrovnávaciu pamäť v polovici až na konci 80. rokov, často len 4 KB. Tento počet časom narastal a typické procesory majú teraz približne 512 KB, zatiaľ čo výkonnejšie procesory sa dodávajú s 1 alebo 2, či dokonca 4, 6, 8 alebo 12 MB, usporiadanými vo viacerých úrovniach pamäťovej hierarchie. Vo všeobecnosti platí, že väčšia vyrovnávacia pamäť znamená vyššiu rýchlosť.
Cache a pipelines sa k sebe dokonale hodili. Predtým nemalo veľký zmysel vytvárať pipeline, ktorá by mohla pracovať rýchlejšie, ako je latencia prístupu k hotovostnej pamäti mimo čipu. Použitie vyrovnávacej pamäte na čipe namiesto toho znamenalo, že pipeline mohla bežať rýchlosťou prístupovej latencie vyrovnávacej pamäte, teda oveľa kratší čas. To umožnilo zvyšovať pracovné frekvencie procesorov oveľa rýchlejšie, ako je to v prípade pamäte mimo čipu.
Predpovedanie vetiev a špekulatívne vykonávanie
Dve hlavné veci, ktoré bránia dosiahnutiu vyššieho výkonu prostredníctvom paralelizmu na úrovni inštrukcií, sú zasekávanie potrubia a vyprázdňovanie v dôsledku vetvenia. Od okamihu, keď dekodér inštrukcií procesora zistí, že narazil na podmienenú inštrukciu vetvenia, až do okamihu, keď sa môže prečítať rozhodujúca hodnota registra skoku, môže byť pipeline zastavená na niekoľko cyklov. V priemere každá piata vykonaná inštrukcia je vetvenie, takže ide o vysoký počet zdržaní. Ak sa vykoná vetvenie, je to ešte horšie, pretože potom sa musia prepláchnuť všetky nasledujúce inštrukcie, ktoré boli v pipeline.
Na zníženie týchto pokút za vetvenie sa používajú techniky ako predikcia vetiev a špekulatívne vykonávanie. Pri predpovedaní vetiev hardvér odhaduje, či sa určitá vetva vykoná. Tento odhad umožňuje hardvéru prefetchovať inštrukcie bez čakania na čítanie registrov. Špekulatívne vykonávanie je ďalším vylepšením, pri ktorom sa kód pozdĺž predpovedanej cesty vykoná skôr, ako sa zistí, či sa má vetva vykonať alebo nie.
Vykonanie mimo poradia
Pridanie vyrovnávacej pamäte znižuje frekvenciu alebo trvanie prestojov spôsobených čakaním na načítanie údajov z hierarchie hlavnej pamäte, ale týchto prestojov sa úplne nezbaví. V prvých návrhoch by zmeškanie vyrovnávacej pamäte prinútilo radič vyrovnávacej pamäte zastaviť procesor a čakať. Samozrejme, v programe môže byť nejaká iná inštrukcia, ktorej údaje sú v tom momente dostupné v cache. Vykonávanie mimo poradia umožňuje, aby sa táto pripravená inštrukcia spracovala, zatiaľ čo staršia inštrukcia čaká na vyrovnávaciu pamäť, a potom zmení poradie výsledkov, aby sa zdalo, že všetko prebehlo v naprogramovanom poradí.
Superskalárne
Aj napriek všetkej pridanej zložitosti a hradlám potrebným na podporu vyššie uvedených konceptov umožnili zlepšenia vo výrobe polovodičov čoskoro použiť ešte viac logických hradiel.
Vo vyššie uvedenom náčrte procesor spracováva časti jednej inštrukcie naraz. Počítačové programy by sa mohli vykonávať rýchlejšie, keby sa súčasne spracúvalo viac inštrukcií. To sa v superskalárnych procesoroch dosahuje replikáciou funkčných jednotiek, ako sú ALU. Replikácia funkčných jednotiek bola možná až vtedy, keď plocha integrovaného obvodu (niekedy nazývaná "die") jednočlánkového procesora už nepresahovala hranice toho, čo sa dalo spoľahlivo vyrobiť. Koncom 80. rokov 20. storočia sa na trh začali dostávať superskalárne návrhy.
V moderných návrhoch sa bežne vyskytujú dve jednotky načítania, jedna jednotka ukladania (mnohé inštrukcie nemajú žiadne výsledky na ukladanie), dve alebo viac celočíselných matematických jednotiek, dve alebo viac jednotiek s pohyblivou rádovou čiarkou a často aj nejaká jednotka SIMD. Logika vydávania inštrukcií narastá na zložitosti čítaním obrovského zoznamu inštrukcií z pamäte a ich odovzdávaním rôznym vykonávacím jednotkám, ktoré sú v danom okamihu nečinné. Výsledky sa potom na konci zhromaždia a znovu zoradia.
Premenovanie registra
Premenovanie registrov sa vzťahuje na techniku používanú na zabránenie zbytočnému sériovému vykonávaniu programových inštrukcií z dôvodu opakovaného používania tých istých registrov týmito inštrukciami. Predpokladajme, že máme skupiny inštrukcií, ktoré budú používať ten istý register, jedna sada inštrukcií sa vykoná ako prvá, aby sa register prenechal druhej sade, ale ak je druhá sada priradená k inému podobnému registru, obe sady inštrukcií sa môžu vykonávať paralelne.
Multiprocesing a viacvláknové spracovanie
Vzhľadom na rastúci rozdiel medzi pracovnými frekvenciami procesora a prístupovými časmi k pamäti DRAM nemohla žiadna z techník, ktoré zvyšujú paralelizmus na úrovni inštrukcií (ILP) v rámci jedného programu, prekonať dlhé zdržania (oneskorenia), ktoré vznikali pri načítavaní údajov z hlavnej pamäte. Okrem toho veľký počet tranzistorov a vysoké pracovné frekvencie potrebné pre pokročilejšie techniky ILP si vyžadovali úroveň rozptylu energie, ktorú už nebolo možné lacno chladiť. Z týchto dôvodov sa v novších generáciách počítačov začali využívať vyššie úrovne paralelizmu, ktoré existujú mimo jedného programu alebo programového vlákna.
Tento trend sa niekedy označuje ako "priepustné výpočty". Táto myšlienka vznikla na trhu mainframov, kde sa pri online spracovaní transakcií kládol dôraz nielen na rýchlosť vykonania jednej transakcie, ale aj na schopnosť zvládnuť veľké množstvo transakcií súčasne. Vzhľadom na to, že v poslednom desaťročí výrazne vzrástol počet aplikácií založených na transakciách, ako je smerovanie po sieti a obsluha webových stránok, počítačový priemysel opäť zdôraznil otázky kapacity a priepustnosti.
Jednou z techník, ako tento paralelizmus dosiahnuť, sú multiprocesorové systémy, počítačové systémy s viacerými CPU. V minulosti to bolo vyhradené pre špičkové mainframy, ale v súčasnosti sa multiprocesorové servery malého rozsahu (2-8) stali bežnou súčasťou trhu malých podnikov. Pre veľké spoločnosti sú bežné veľké multiprocesory (16 - 256). Od 90. rokov sa objavili dokonca aj osobné počítače s viacerými procesormi.
Pokroky v polovodičovej technológii zmenšili veľkosť tranzistorov; objavili sa viacjadrové procesory, v ktorých je na jednom kremíkovom čipe implementovaných viacero procesorov. Spočiatku sa používali v čipoch zameraných na vstavané trhy, kde jednoduchšie a menšie CPU umožňovali, aby sa na jeden kus kremíka zmestilo viacero inštancií. Do roku 2005 umožnila polovodičová technológia sériovú výrobu dvoch špičkových desktopových CPU čipov CMP. Niektoré návrhy, ako napríklad UltraSPARC T1, používali jednoduchšie (skalárne, v poradí) návrhy, aby sa na jeden kus kremíka zmestilo viac procesorov.
V poslednom čase je čoraz populárnejšia ďalšia technika, ktorou je multithreading. Pri multithreadingu, keď má procesor načítať údaje z pomalej systémovej pamäte, namiesto toho, aby čakal na príchod údajov, procesor sa prepne na iný program alebo programové vlákno, ktoré je pripravené na vykonávanie. Hoci sa tým nezrýchli konkrétny program/vlákno, zvýši sa celková priepustnosť systému tým, že sa skráti čas nečinnosti procesora.
Koncepčne je multithreading ekvivalentný prepínaniu kontextu na úrovni operačného systému. Rozdiel je v tom, že viacvláknový procesor môže prepnúť vlákno za jeden cyklus procesora namiesto stoviek alebo tisícok cyklov procesora, ktoré si prepínanie kontextu zvyčajne vyžaduje. Dosahuje sa to replikáciou stavového hardvéru (napríklad súboru registrov a programového čítača) pre každé aktívne vlákno.
Ďalším vylepšením je simultánny multithreading. Táto technika umožňuje superskalárnym procesorom vykonávať inštrukcie z rôznych programov/vlákien súčasne v tom istom cykle.
Súvisiace stránky
- Mikroprocesor
- Mikrokontrolér
- Viacjadrový procesor
- Procesor digitálneho signálu
- Konštrukcia CPU
- Datapath
- paralelizmus na úrovni inštrukcií (ILP)
Otázky a odpovede
Otázka: Čo je to mikroarchitektúra?
Odpoveď: Mikroarchitektúra je opis elektrických obvodov počítača, centrálnej procesorovej jednotky alebo digitálneho signálového procesora, ktorý postačuje na úplný opis činnosti hardvéru.
Otázka: Ako vedci označujú tento pojem?
Odpoveď: Vedci používajú pojem "organizácia počítača", keď hovoria o mikroarchitektúre.
Otázka: Ako tento pojem označujú ľudia v počítačovom priemysle?
Odpoveď: Ľudia v počítačovom priemysle častejšie hovoria "mikroarchitektúra", keď hovoria o tomto pojme.
Otázka: Ktoré dve oblasti tvoria architektúru počítača?
Odpoveď: Mikroarchitektúra a architektúra inštrukčnej sady (ISA) spolu tvoria oblasť počítačovej architektúry.
Otázka: Čo znamená skratka ISA?
Odpoveď: ISA je skratka pre architektúru inštrukčnej sady.
Otázka: Čo znamená skratka µarch? O: µArch je skratka pre mikroarchitektúru.
Súvisiace články
Autor
AlegsaOnline.com Mikroarchitektúra procesora (CPU): definícia, funkcie a rozdiel od ISA Leandro Alegsa
URL: https://sk.alegsaonline.com/art/64586
Zdroje
- computer.org : IEEE Computer Society
- extremetech.com : PC Processor Microarchitecture