Zipfov zákon – definícia, príklady a význam pre frekvenciu slov
Zipfov zákon: jasná definícia, praktické príklady a význam pre analýzu frekvencie slov v texte — pochopte, prečo niektoré slová dominujú.
Zipfov zákon je empirický zákon formulovaný pomocou matematickej štatistiky, pomenovaný podľa lingvistu Georgea Kingsleyho Zipfa, ktorý ho navrhol ako prvý.
V najjednoduchšej forme Zipfov zákon hovorí, že pri veľkej vzorke použitých slov je ich frekvencia nepriamo úmerná ich poradiu v triedenom zozname podľa frekvencie. Inými slovami: slovo s poradím r (rank) má frekvenciu približne úmernú 1/r. To sa zvykne zapisovať matematicky ako f(r) ∝ 1 / r^s, kde zvyčajne s ≈ 1. Pri s = 1 ide o čistú Zipfovu podobu; obecnejší tvar, ktorý lepšie sedí na niektoré dátové súbory, je Zipf–Mandelbrotov zákon f(r) ∝ 1 / (r + q)^s, kde q je posun pre korigovanie najfrekventovanejších položiek.
Praktický dôsledok: najfrekventovanejšie slovo sa bude vyskytovať približne dvakrát častejšie ako druhé, trikrát častejšie ako tretie atď. Napríklad v jednej veľkej anglickej vzorke tvorí najčastejšie slovo "the" takmer 7 % všetkých slov (69 971 z niečo viac ako 1 milióna). V súlade so Zipfovým zákonom slovo "of", ktoré je na druhom mieste, predstavuje niečo vyše 3,5 % slov (36 411 výskytov), za ním nasleduje slovo "and" (28 852). Na to, aby sa vo veľkej vzorke vyskytla polovica všetkých slov, je potrebných len približne 135 rôznych slov.
Galéria obrázkov
3 Obrázky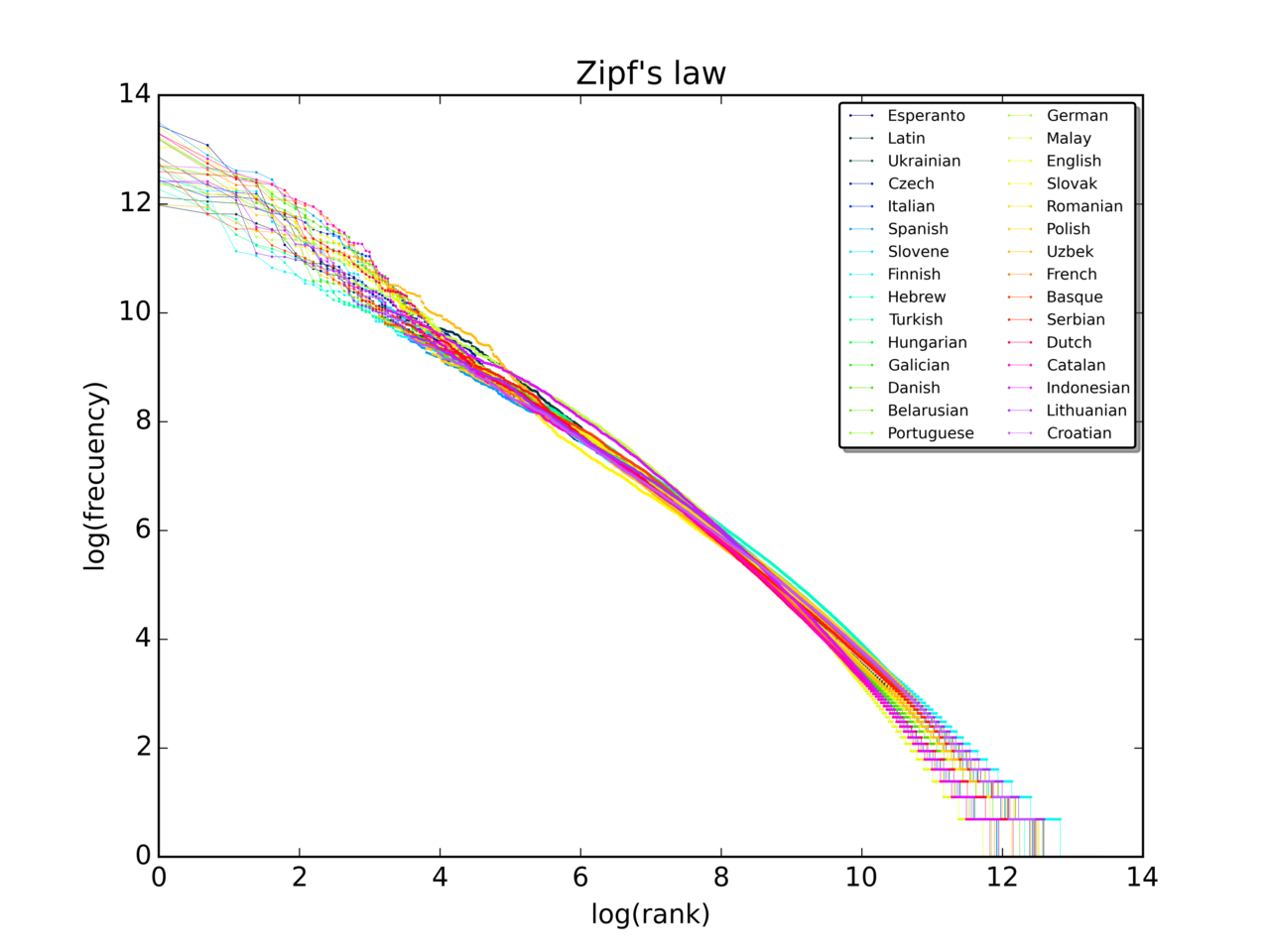


Vzory a výskyt mimo jazyka
Tento typ rozdelenia sa neobjavuje len v jazyku. Rovnaký vzťah možno nájsť v mnohých iných rebríčkoch a javy: počty obyvateľov miest v rôznych štátoch, veľkosti podnikov, príjmové distribúcie, počet odkazov na webové stránky, počet stiahnutí aplikácií a pod. Výskyt rozdelenia v rebríčkoch miest podľa počtu obyvateľov si prvýkrát všimol Felix Auerbach v roku 1913.
Ako zákon overiť a merať
- Najbežnejšia vizualizácia: graf frekvencie proti poradí v log‑log súradniciach. Zipfov zákon sa prejaví ako priamka so sklonom približne −1.
- Štatistické testovanie: namiesto jednoduchého odhadu pomocou lineárnej regresie v log‑log priestore sa odporúča použiť metódy ako maximálna vierohodnosť (MLE) pre power‑law, test kolmogorov‑smirnov a porovnanie s alternatívnymi modelmi (napr. lognormálne alebo exponenciálne chvosty).
- Pozor na artefakty: malé korpusy, tokenizačné pravidlá, morfologická variabilita (skloňovanie, zložené slová) a predspracovanie textu môžu výrazne ovplyvniť zistené rozdelenie.
Možné vysvetlenia
Prečo Zipfov zákon funguje, nie je úplne jednoznačné a ide o predmet dlhoročnej debaty. Medzi navrhované vysvetlenia patria:
- Princip "najmenšieho úsilia" (Zipfova hypotéza): jazyk a komunikácia sa vyvíjajú tak, aby minimalizovali kognitívnu námahu hovoriacich a počítajú s kompromisom medzi námahou hovoriaceho (používanie krátkych, frekventovaných slov) a presnosťou pre poslucháča.
- Preferenčné pripojovanie (Simonov model): počas formovania záznamov (napríklad textov alebo sietí) sa novým položkám s vyššou pravdepodobnosťou pridávajú ďalšie výskyty, čo vedie k bohatým‑na‑bohatých efektom a mocninnému zákonu.
- Náhodné modely (napr. model "násilného písania" alebo "monkey‑typing"): jednoduché náhodné generovanie znakov s určitými pravidlami môže viesť k približnému Zipfovmu rozdeleniu—aj keď tieto modely často nedokážu zachytiť všetky štruktúry prirodzeného jazyka.
- Informačno‑teoretické vysvetlenia: optimalizácia prenesenia informácií pri obmedzených kapacitách kanála môže viesť k rovnováhe medzi entropiou a redundanciou, čo sa prejavuje vo frekvenčnom rozdelení slov.
Praktický význam
Zipfov zákon má viacero praktických dôsledkov:
- V oblasti spracovania prirodzeného jazyka (NLP) ovplyvňuje návrh slovníkov, techniky tokenizácie, vyhľadávanie a metódy znižovania dimenzie — malé množstvo slov (stop‑words) pokrýva veľkú časť textu.
- V informatiky a indexovaní: frekvencia slov sa využíva v metrikách ako TF‑IDF; Zipfovo rozdelenie vysvetľuje, prečo sú bežné slová málo informatívne pre odlíšenie dokumentov.
- V kompresii dát: znalosť distribuovaného jazyka vedie k efektívnejšiemu kódovaniu častejších tokenov kratšími kódmi.
- V sociálnych a ekonomických analýzach: predpoklad o mocninných rozdeleniach pomáha modelovať veľkosti miest, bohatstvo a ďalšie fenomény s výraznými nerovnosťami.
Obmedzenia a odchýlky
Zipfov zákon nie je univerzálny zákon bez výnimiek. Typické problémy a obmedzenia:
- V reálnych údajoch často dochádza k odchýlkam v extrémoch – veľmi frekventované aj veľmi zriedkavé položky nemusia presne sledovať ideálnu 1/r krivku.
- Rôzne jazyky a typy korpusov (hovorený vs. písaný text, odborné texty, sociálne siete) vykazujú odlišné parametre s a posuny q.
- Jednoduché log‑log priamky s vysokým R² môžu viesť k prehnanej istote; robustné štatistické testy sú nevyhnutné pre spoľahlivé závery.
Zhrnutie
Zipfov zákon poskytuje užitočné a často prekvapujúce pozorovanie o tom, ako sú slová (a mnohé ďalšie veličiny) rozdelené podľa frekvencie: niekoľko málo položiek tvorí veľkú časť všetkých výskytov, zatiaľ čo väčšina položiek sa vyskytuje veľmi zriedka. Hoci presný mechanizmus zostáva predmetom diskusií, zákon má široké aplikácie v lingvistike, informatike, ekonómii a ďalších odboroch a je dobrým východiskom pri modelovaní a analýze dát založených na frekvenciách.
Nie je známe, prečo Zipfov zákon platí pre väčšinu jazykov; existuje však mnoho hypotéz a modelov, ktoré sa snažia tento fenomén vysvetliť a ktoré ho zároveň úspešne využívajú v praxi.
Otázky a odpovede
Otázka: Čo je Zipfov zákon?
Odpoveď: Zipfov zákon je empirický zákon, ktorý hovorí, že frekvencia slova vo veľkej vzorke je nepriamo úmerná jeho poradiu v tabuľke frekvencií.
Otázka: Kto navrhol Zipfov zákon?
Odpoveď: Zipfov zákon prvýkrát navrhol lingvista George Kingsley Zipf.
Otázka: Ako Zipfov zákon vysvetľuje frekvenciu slov vo vzorke anglických slov?
Odpoveď: Podľa Zipfovho zákona sa najfrekventovanejšie slovo vo vzorke anglických slov vyskytuje približne dvakrát častejšie ako druhé najfrekventovanejšie slovo, trikrát častejšie ako tretie najfrekventovanejšie slovo atď. Tento trend pokračuje s klesajúcou hodnosťou slova.
Otázka: Aké percento všetkých slov tvorí najčastejšie sa vyskytujúce slovo v jednej vzorke anglických slov?
Odpoveď: V jednej vzorke anglických slov tvorí najčastejšie sa vyskytujúce slovo ("the") takmer 7 % všetkých slov.
Otázka: Aký je vzťah medzi počtom slov potrebných na vytvorenie polovice vzorky a frekvenciou týchto slov?
Odpoveď: Podľa Zipfovho zákona je vo veľkej vzorke potrebných len približne 135 slov na to, aby sa vyjadrila polovica slov.
Otázka: Ktoré ďalšie rebríčky vykazujú Zipfov zákon?
Odpoveď: Rovnaký vzťah, aký opisuje Zipfov zákon pri frekvencii slov, sa vyskytuje aj v iných rebríčkoch, ktoré nesúvisia s jazykom, napríklad v rebríčkoch počtu obyvateľov miest v rôznych krajinách, veľkosti korporácií a príjmov.
Otázka: Kto si všimol výskyt rozdelenia v rebríčkoch miest podľa počtu obyvateľov?
Odpoveď: Výskyt distribúcie v rebríčkoch miest podľa počtu obyvateľov si ako prvý všimol Felix Auerbach v roku 1913.
Súvisiace články
Autor
AlegsaOnline.com Zipfov zákon – definícia, príklady a význam pre frekvenciu slov Leandro Alegsa
URL: https://sk.alegsaonline.com/art/110649
Zdroje
- books.google.com : P. 139